

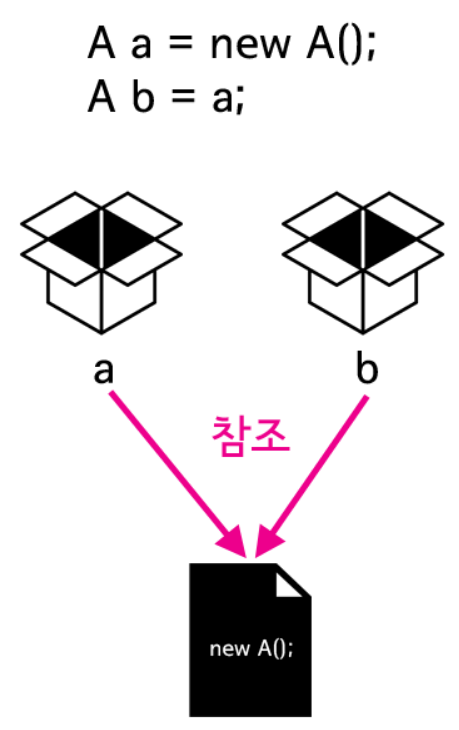
참조
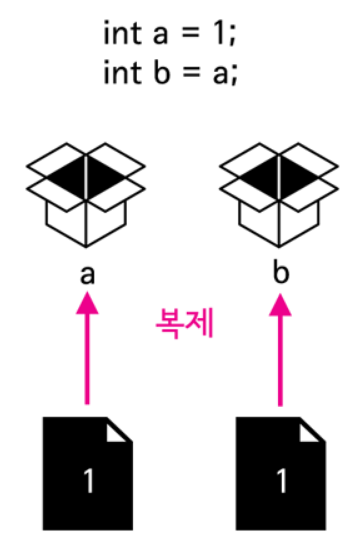
복제
new를 붙이는 데이터형은 참조 데이터형이며 그 외 char, int 등은 기본 데이터형이다.
public class ReferenceDemo1 {
public static void runValue(){
int a = 1;
int b = a;
b = 2;
System.out.println("runValue, "+a);
}
public static void main(String[] args) {
runValue();
}
}// 실행 결과
runValue, 1a라는 상자에다가 1을 넣고, b라는 상자는 a 상자 안에 있는 값으로 복제한다.
b라는 상자에 값을 2로 다시 넣는다고 한들 a 상자 안에 값을 변하지 않는다.
참조
class A{
public int id;
A(int id){
this.id = id;
}
}
public class ReferenceDemo1 {
public static void runValue(){
int a = 1;
int b = a;
b = 2;
System.out.println("runValue, "+a);
}
public static void runReference(){
A a = new A(1);
A b = a;
b.id = 2;
System.out.println("runReference, "+a.id);
}
public static void main(String[] args) {
runValue();
runReference();
}
}// 실행 결과
runValue, 1
runReference, 2위 코드와의 차이점은 runReference 메소드를 추가했다는 점이다.
참조형 데이터 타입 A인 객체 a를 만들어준 후 동일한 데이터 타입의 객체 b를 a를 활용하여 복제한다.
그 후 b의 id값을 변경해주면 a의 id값을 데이터타입이 기본형이였을 때와 달리 변경되어 2과 출력된다.
기본 데이터 타입일 경우 택배 상자에 담긴 값을 가져오는 것으로 복제가 된다면
참조형 데이터 타입의 경우
A a = new A(1)은 A라는 인스턴스의 1이라는 값을 넣고 A 인스턴스의 주소를 a가 참조한다는 의미이다.
그렇기에 A b = a는 a가 참조하는 주소 즉, A 인스턴스를 참조하겠다는 의미이기에
b.id = 2를 하게 되면 A인스턴스의 값이 바뀌게 되어 이를 참조하는 a까지도 값이 바뀌게 된다.
참조와 복제
이해를 돕기 위한 비유를 드는 영상으로 이해가 이미 되었다면 넘어가도 된다.
- 복제는 복사와 같다.
- 참조는 바로 가기와 같다
참조 데이터 형과 매개 변수
public class ReferenceParameterDemo {
static void _value(int b){
b = 2;
}
public static void runValue(){
int a = 1;
_value(a);
System.out.println("runValue, "+a);
}
static void _reference1(A b){
b = new A(2);
}
public static void runReference1(){
A a = new A(1);
_reference1(a);
System.out.println("runReference1, "+a.id);
}
static void _reference2(A b){
b.id = 2;
}
public static void runReference2(){
A a = new A(1);
_reference2(a);
System.out.println("runReference2, "+a.id);
}
public static void main(String[] args) {
runValue(); // runValue, 1
runReference1(); // runReference1, 1
runReference2(); // runReference2, 2
}
}// 실행 결과
runValue, 1
runReference1, 1
runReference2, 2- runValue 메소드는 a 택배 상자에 1을 넣고 _value 메소드의 인자로 a를 전달합니다. _value 메소드에서는 b 택배 상자에 2를 넣습니다. 다시 runValue 메소드로 돌아와 a를 출력하면 2가 출력됩니다. 기본 데이터 타입이기 때문에 b의 값을 아무리 변경하여도 a의 값을 변경되지 않습니다.
- runReference1 메소드는 값 1을 담고 있는 A 인스턴스를 참조하는 A 데이터 타입의 a 객체를 만든 후 _reference1 메소드의 인자로 a를 전달합니다. _reference1 메소드에서는 값 2를 담고 있는 A 인스턴스를 새롭게 만들어준 후 이를 A 데이터 타입의 b 객체가 참조합니다. 다시 runReference1 메소드로 돌아와 a.id를 출력하면 1이 나옵니다.
- runReference2는 runReference1과 동일하지만 _reference2 메소드에서 새로 인스턴스를 만들어 참조하는 것이 아닌 기존 A 인스턴스를 참조하여 값을 2로 변경해주었습니다. 그렇기에 a.id를 출력하면 2가 나옵니다.
제네릭
제네릭의 사용법
제네릭(Generic)은 클래스 내부에서 사용할 데이터 타입을 외부에서 지정하는 기법이다.
class Person<T>{
public T info;
}
public class GenericDemo {
public static void main(String[] args) {
Person<String> p1 = new Person<String>();
Person<StringBuilder> p2 = new Person<StringBuilder>();
}
}- Person 클래스를 만들어 줄 때 매개변수가 작성되어야 할 곳에 <T>를 작성한다.
- Person 클래스의 필드 info의 데이터 타입은 T로 지정되어 있다.
- 이 클래스를 사용하여 객체를 생성해줄 때 <> 안에 데이터 타입을 작성해준다.
- 해당 데이터 타입으로 info가 생성된다.
즉 클래스를 정의할 때 info의 데이터 타입을 확정하지 않고 인스턴스를 생성할 때 데이터 타입을 지정하는 기능이 제네릭이다.
제네릭의 사용 이유
- 컴파일 단계에서 오류가 검출된다
- 중복의 제거와 타입 안전성을 동시에 추구할 수 있게 된다.
타입 안전성
Object로 데이터 타입을 지정할 경우 의도와는 다른 데이터 타입이 들어올 수 있게 되기에 타입을 지정하여 의도대로 코드가 실행되게끔 프로그래밍하는 것을 말한다.
제네릭의 특징
1. 복수의 제네릭
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class Person<T, S>{
public T info;
public S id;
Person(T info, S id){
this.info = info;
this.id = id;
}
}
public class GenericDemo {
public static void main(String[] args) {
EmployeeInfo e = new EmployeeInfo(1);
Integer i = new Integer(10);
Person<EmployeeInfo, Integer> p1 = new Person<EmployeeInfo, Integer>(e, i);
System.out.println(p1.id.intValue());
}
}2. 기본 데이터 타입과 제네릭
- 제네릭은 참조 데이터 타입에 대해서만 사용되기 때문에 기본 데이터 타입에서는 사용할 수 없다.
- new Integer는 기본 데이터 타입인 int를 참조 데이터 타입으로 변환해주는 역할을 한다. 이러한 클래스를 래퍼(wrapper) 클래스 라고 한다.
3. 생략
EmployeeInfo e = new EmployeeInfo(1);
Integer i = new Integer(10);
// 아래 두 코드는 동일하게 동작
Person<EmployeeInfo, Integer> p1 = new Person<EmployeeInfo, Integer>(e, i);
Person p2 = new Person(e, i);
4. 메소드에 적용
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class Person<T, S>{
public T info;
public S id;
Person(T info, S id){
this.info = info;
this.id = id;
}
public <U> void printInfo(U info){
System.out.println(info);
}
}
public class GenericDemo {
public static void main(String[] args) {
EmployeeInfo e = new EmployeeInfo(1);
Integer i = new Integer(10);
Person<EmployeeInfo, Integer> p1 = new Person<EmployeeInfo, Integer>(e, i);
p1.<EmployeeInfo>printInfo(e);
p1.printInfo(e);
}
}
제네릭의 제한
1. extends
제네릭으로 올 수 있는 데이터 타입을 특정 클래스의 자식으로 제한할 수 있다.
abstract class Info{
public abstract int getLevel();
}
class EmployeeInfo extends Info{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
public int getLevel(){
return this.rank;
}
}
class Person<T extends Info>{
public T info;
Person(T info){ this.info = info; }
}
public class GenericDemo {
public static void main(String[] args) {
Person p1 = new Person(new EmployeeInfo(1));
Person<String> p2 = new Person<String>("부장");
}
}Person 클래스를 보면 info를 T가 상속받고 있다.
T는 info 클래스나 그 자식 외에는 올 수 없다.
implements로도 제네릭을 제한할 수 있다.
interface Info{
int getLevel();
}
class EmployeeInfo implements Info{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
public int getLevel(){
return this.rank;
}
}
class Person<T extends Info>{
public T info;
Person(T info){ this.info = info; }
}
public class GenericDemo {
public static void main(String[] args) {
Person p1 = new Person(new EmployeeInfo(1));
Person<String> p2 = new Person<String>("부장");
}
}
Collections Framework
ArrayList의 사용법
배열은 초기에 정한 배열의 크기를 변경할 수 없다는 단점이 있다.
ArrayList는 크기를 미리 지정하지 않기 때문에 얼마든지 많은 수의 값을 저장할 수 있다.
import java.util.ArrayList;
public class ArrayListDemo{
public static void main(String[] args){
ArrayList<String> al = new ArrayList<String>();
al.add("one");
al.add("two");
al.add("three");
for(int i=0; i<al.size(); i++){
String val = al.get(i);
System.out.println(val);
}
}
}add의 인자는 Object 타입이다.
그렇기 때문에 강제적 형변환을 해주거나 위 코드와 같이 제네릭을 활용해주어야 한다.
전체적인 구성
컬렉션 프레임워크는 값을 담는 그릇이라는 의미로 컨테이너라고도 부른다.
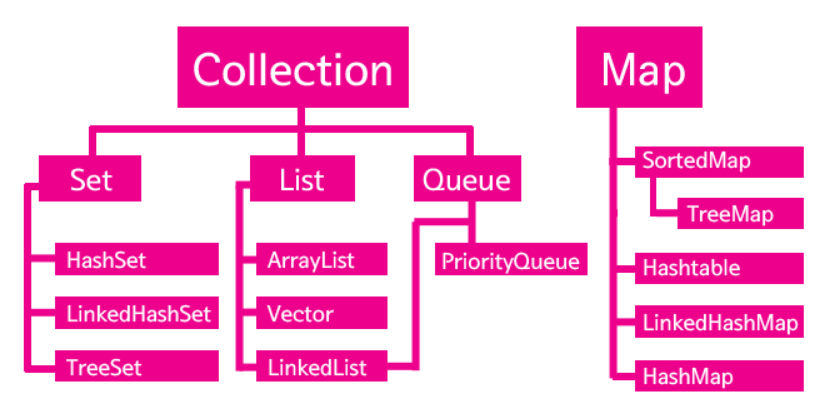
List와 Set의 차이점
List는 중복을 허용하고 저장되는 순서가 유지되지만,
Set은 중복이 허용하지 않고 순서가 없다.
Set
set은 한국어로 집합이라는 뜻이다.
수학에서의 집합과 같은 의미이기에 교집합, 차집합, 합집합과 같은 연산을 할 수 있다.
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
public class SetDemo {
public static void main(String[] args) {
HashSet<Integer> A = new HashSet<Integer>();
A.add(1);
A.add(2);
A.add(3);
HashSet<Integer> B = new HashSet<Integer>();
B.add(3);
B.add(4);
B.add(5);
HashSet<Integer> C = new HashSet<Integer>();
C.add(1);
C.add(2);
// 부분집합
// B는 A의 부분집합인가
System.out.println(A.containsAll(B)); // false
// C는 A의 부분집합인가
System.out.println(A.containsAll(C)); // true
A.addAll(B); // AUB
A.retainAll(B); // AnB
A.removeAll(B); // A-B
}
}
Collection Interface
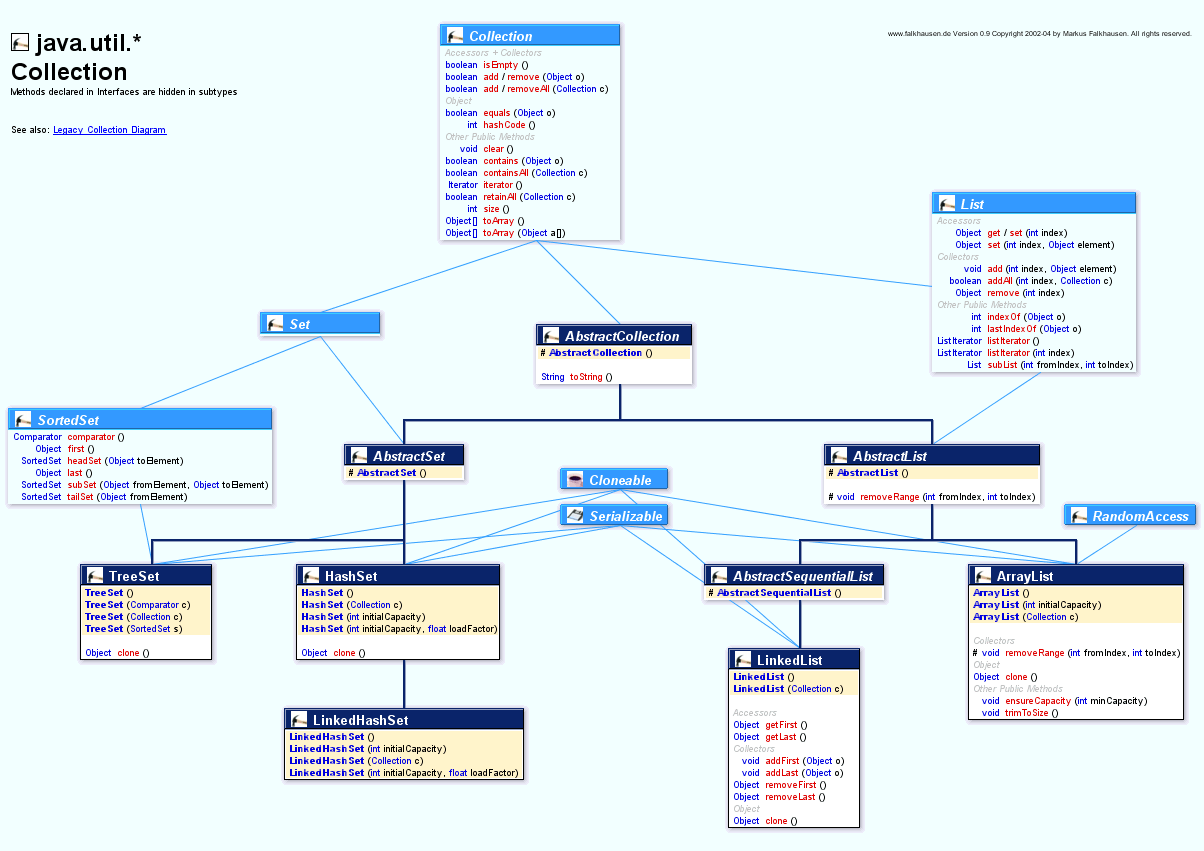
하늘색은 인터페이스, 파랑색은 클래스이다.
인터페이스를 구현하는 클래스들은 인터페이스가 갖고 있는 메소드를 갖는다.
iterator
iterator(반복자)는 Collection 인터페이스에 정의되어있어 Collection을 구현하는 모든 컬렉션즈 프레임워크는 이 메소드를 갖고 있다. iterator는 아래 메소드를 구현하도록 강제하고 있다.
- hasNext : 반복할 데이터가 더 있으면 true, 없다면 false를 리턴한다.
- next : hasNext가 true라는 것은 next가 리턴할 데이터가 존재한다는 의미다.
위 기능들을 조합하면 데이터를 순차적으로 처리할 수 있다.
import java.util.HashSet;
import java.util.Iterator;
public class SetDemo{
public static void main(String[] args){
HashSet<Integer> A = new HashSet<Integer>();
A.add(1);
A.add(2);
A.add(3);
Iterator hi = A.iterator();
while(hi.hasNext()){
System.out.println(hi.next());
}
}
}hi하는 Iterator 타입에 A 안에 있는 값들을 순서대로 넣어준다.
hi에 값이 있다면 해당 값을 출력해주고 삭제한다.
다음 값이 있다면 출력하고 삭제하고를 반복하다 다음 값이 없으면 while문이 종료된다.
hi에 있는 값이 삭제될 뿐 A에는 영향을 주지 않는다.
Map
Map 컬렉션은 key와 value의 쌍으로 값을 저장하는 컬렉션이다.
key값은 중복이 될 수 없지만 value값은 중복값을 허용한다.
import java.util.*;
public class MapDemo {
public static void main(String[] args) {
HashMap<String, Integer> a = new HashMap<String, Integer>();
a.put("one", 1);
a.put("two", 2);
a.put("three", 3);
a.put("four", 4);
System.out.println(a.get("one")); // 1
System.out.println(a.get("two")); // 2
System.out.println(a.get("three")); // 3
iteratorUsingForEach(a);
iteratorUsingIterator(a);
}
static void iteratorUsingForEach(HashMap map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
static void iteratorUsingIterator(HashMap map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Iterator<Map.Entry<String, Integer>> i = entries.iterator();
while(i.hasNext()){
Map.Entry<String, Integer> entry = i.next();
System.out.println(entry.getKey()+" : "+entry.getValue());
}
}
}entrySet은 Map의 데이터를 담고 있는 Set을 반환한다. 반환한 Set의 값이 사용할 데이터 타입은 Map.Entry이다. Map.Entry는 인터페이스인데 getKey, getValue를 통해 Map의 key,와 value를 조회한다.
Collections의 사용
import java.util.*;
class Computer implements Comparable{
int serial;
String owner;
Computer(int serial, String owner){
this.serial = serial;
this.owner = owner;
}
public int compareTo(Object o) {
return this.serial - ((Computer)o).serial;
}
public String toString(){
return serial+" "+owner;
}
}
public class CollectionsDemo {
public static void main(String[] args) {
List<Computer> computers = new ArrayList<Computer>();
computers.add(new Computer(500, "egoing"));
computers.add(new Computer(200, "leezche"));
computers.add(new Computer(3233, "graphittie"));
Iterator i = computers.iterator();
System.out.println("before");
while(i.hasNext()){
System.out.println(i.next());
}
Collections.sort(computers);
System.out.println("\nafter");
i = computers.iterator();
while(i.hasNext()){
System.out.println(i.next());
}
}
}// 실행 결과
before
500 egoing
200 leezche
3233 graphittie
after
200 leezche
500 egoing
3233 graphittieCollectors 클래스가 제공하는 다양한 메소드 중 sort는 List의 정렬을 수행한다.
sort는 아래와 같이 정의되어있다.
public static <T extends Comparable<? super T>> void sort(List<T> list)인자로 List 데이터타입의 제네릭 <T>인 list를 받고 있으며
T는 comparable을 extends하고 있어야 한다.
comparable은 인터페이스이기에 이를 구현하는 메소드를 compareTo로 만들어줬다.
'JAVA > [생활코딩] 자바' 카테고리의 다른 글
| [생활코딩] 예외 처리, Object 클래스, 상수와 enum (0) | 2023.04.30 |
|---|---|
| [생활코딩] 접근 제어자, abstract, final, 인터페이스, 다형성 (1) | 2023.04.17 |
| [생활코딩] overriding, overloading, 클래스 패스, 패키지, API와 API 문서 보는 법 (0) | 2023.04.09 |
| [생활코딩] 자바 유효범위, 초기화와 생성자, 상속, 상속과 생성자 (0) | 2023.03.31 |
| [생활코딩] 자바 객체지향프로그래밍, 클래스와 인스턴스 그리고 객체, 클래스 멤버와 인스턴스 멤버 (0) | 2023.03.31 |